Embedding in Machine Learning
What is Embedding?
Embedding in the context of deep learning is to map high-dimensional vectors or categorical variables to relatively low-dimensional space so that similar items are close to each other. It can be applied to any high dimensional, sparse or categorical features, i.e., IP addresses from ad impressions, raw pixels in a video, audio data from speech, texts from a job description.
The logic of embedding is to break down categories into the constituent feature that makes that categorical value informative in the first place (versus simply throwing it in as a one-hot encoding). Therefore, it overcomes two major drawbacks of one-hot encoding:
- The dimensionality of the transformed vector of high-cardinality variables becomes unmanageable.
- The distance of the mapping in the embedding space tells little about the similarity of the variable values.
Neural network embeddings have 3 primary purposes:
- Finding nearest neighbors in the embedding space. These can be used to make recommendations based on user interests or cluster categories.
- As input to a machine learning model for a supervised task. It make it easier to do machine learning on large inputs like sparse vectors representing words.
- For visualization of concepts and relations between categories.
Methods for Embedding
Main methods for embedding includes the following:
- Count-based feature vectorization. That is to aggregate outcomes of a given category by count and build dense features that way. Here are some examples:
- Categorical zip code can be converted to continuous (latitude, longitude) pair.
- Neighborhood of a hotel can be encoded by average daily volume of a 3-star hotel in that neighborhood
-
Principal component analysis. It is a commonly used linear embedding technique to reduce the dimensionality of feature vectors by mapping them to lower dimensional space while retaining most of the feature variance.
-
Word2vec. A word embedding is an approach to provide a dense vector representation of words that capture something about their meaning. Word embeddings work by using an algorithm to train a set of fixed-length dense and continuous-valued vectors based on a large corpus of text. Each word is represented by a point in the embedding space and these points are learned and moved around based on the words that surround the target word. You can use Word2vec to train your own embedding model or use pretrained model (i.e., by Google). Refer here for more details.
- Supervised learning. That is to train an embedding as part of a larger neural network model. Please see the embedding in recommendation system example for details.
Embedding Examples
Embedding in Recommendation Systems
Recommendation system predicts the interest of a user for a given item. Collaborative filtering, which predicts the interests of a user based on the interest of similar users, is the most popular method used to build a recommender system. To solve this problem, we need to know which users are similar to each other and which movies are similar to each other. Thus we need user embeddings and item embeddings. Before using embedding, think about what alternatives do we have? We can always represent each movie with a sparse vector based on user-movie interactions using one-hot encoding. However, the problem of that method is 1) we are going to deal with sparse vectors in our modeling process, which is quite a pain because we need more data and much more computation power to train and 2) similar vector doesn’t mean similar items. That’s why we need to use embedding instead. How? Train an embedding as part of a larger neural network. The problem can be reframed as a supervised learning problem with input as the feature vectors of the movie and output as each user’s interest of the movie (probabilistic multi-class classification problem). Here the input feature vector contains user movie vector which is a sparse vector and any other features. Let’s say there are 5000 movies and 1000 users. Each user movie vector will be 1 x 1000 sparse vector with 1 as like and 0 as not like by the user i (i from 0 to 999). The output will be a 1 x 1000 vector with probability of likes by the user i ( i from 0 to 999). We include a three dimensional embedding layer to convert the sparse user movie vector to a three dimensional embedding layer (see Schema below, from Google). The empirical rule of thumb is the dimension of the embedding layer is approximately (possible values)^0.25 (start with this number and further tune it to get optimal dimension).
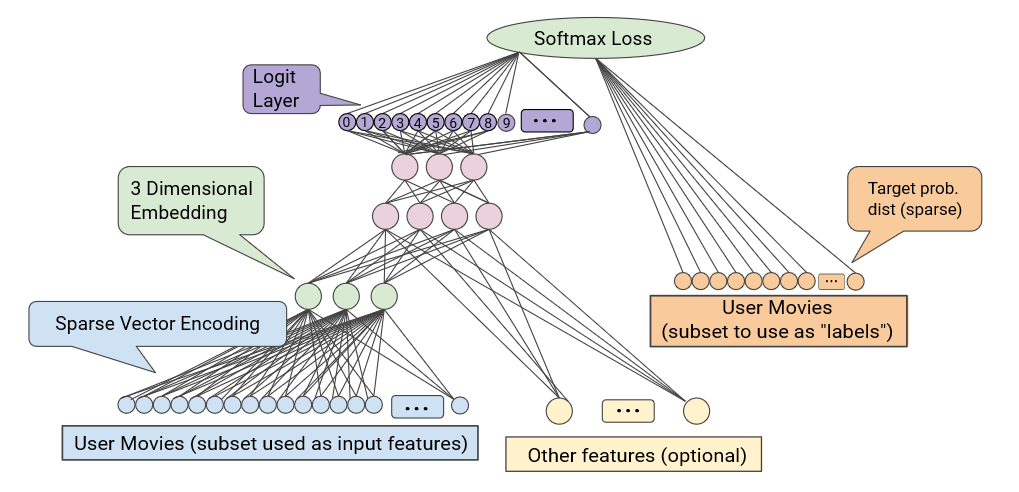
Image embedding
Pinterest example
Embedding Visualization - t-SNE
t-Distributed Stochastic Neighbor Embedding (t-SNE) is a non-linear technique for dimensionality reduction. It tries to map high-dimensional data to a lower-dimensional manifold, creating an embedding that attempts to maintain local structure within the data. It’s almost exclusively used for visualization because the output is stochastic (random) and it does not support transforming new data. Compared to PCA:
- t-SNE is computationally expensive and can take several hours on million-sample datasets where PCA will finish in seconds or minutes.
- PCA is a mathematical technique, but t-SNE is a probabilistic one.
- PCA is a linear method while t-SNE is a non-linear method.
- PCA concentrates on placing dissimilar data points apart in a lower dimension representation while t-SNE tries to represent similar data points close together. Therefore, the cluster segregation is better in the lower dimensional space using t-SNE.
- t-SNE is a stochastic method, meaning different runs with the same hyperparameters may produce different results. On the contrary, PCA is a deterministic method.
References:
- https://www.dslearn.org/embeddings/
- https://towardsdatascience.com/neural-network-embeddings-explained-4d028e6f0526
- https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture
- https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
- https://www.datacamp.com/community/tutorials/introduction-t-sne
- https://towardsdatascience.com/an-introduction-to-t-sne-with-python-example-5a3a293108d1
Embedding in Machine Learning
What is Embedding?
Embedding in the context of deep learning is to map high-dimensional vectors or categorical variables to relatively low-dimensional space so that similar items are close to each other. It can be applied to any high dimensional, sparse or categorical features, i.e., IP addresses from ad impressions, raw pixels in a video, audio data from speech, texts from a job description.
The logic of embedding is to break down categories into the constituent feature that makes that categorical value informative in the first place (versus simply throwing it in as a one-hot encoding). Therefore, it overcomes two major drawbacks of one-hot encoding:
- The dimensionality of the transformed vector of high-cardinality variables becomes unmanageable.
- The distance of the mapping in the embedding space tells little about the similarity of the variable values.
Neural network embeddings have 3 primary purposes:
- Finding nearest neighbors in the embedding space. These can be used to make recommendations based on user interests or cluster categories.
- As input to a machine learning model for a supervised task. It make it easier to do machine learning on large inputs like sparse vectors representing words.
- For visualization of concepts and relations between categories.
Methods for Embedding
Main methods for embedding includes the following:
- Count-based feature vectorization. That is to aggregate outcomes of a given category by count and build dense features that way. Here are some examples:
- Categorical zip code can be converted to continuous (latitude, longitude) pair.
- Neighborhood of a hotel can be encoded by average daily volume of a 3-star hotel in that neighborhood
-
Principal component analysis. It is a commonly used linear embedding technique to reduce the dimensionality of feature vectors by mapping them to lower dimensional space while retaining most of the feature variance.
-
Word2vec. A word embedding is an approach to provide a dense vector representation of words that capture something about their meaning. Word embeddings work by using an algorithm to train a set of fixed-length dense and continuous-valued vectors based on a large corpus of text. Each word is represented by a point in the embedding space and these points are learned and moved around based on the words that surround the target word. You can use Word2vec to train your own embedding model or use pretrained model (i.e., by Google). Refer here for more details.
- Supervised learning. That is to train an embedding as part of a larger neural network model. Please see the embedding in recommendation system example for details.
Embedding Examples
Embedding in Recommendation Systems Recommendation system predicts the interest of a user for a given item. Collaborative filtering, which predicts the interests of a user based on the interest of similar users, is the most popular method used to build a recommender system. To solve this problem, we need to know which users are similar to each other and which movies are similar to each other. Thus we need user embeddings and item embeddings. Before using embedding, think about what alternatives do we have? We can always represent each movie with a sparse vector based on user-movie interactions using one-hot encoding. However, the problem of that method is 1) we are going to deal with sparse vectors in our modeling process, which is quite a pain because we need more data and much more computation power to train and 2) similar vector doesn’t mean similar items. That’s why we need to use embedding instead. How? Train an embedding as part of a larger neural network. The problem can be reframed as a supervised learning problem with input as the feature vectors of the movie and output as each user’s interest of the movie (probabilistic multi-class classification problem). Here the input feature vector contains user movie vector which is a sparse vector and any other features. Let’s say there are 5000 movies and 1000 users. Each user movie vector will be 1 x 1000 sparse vector with 1 as like and 0 as not like by the user i (i from 0 to 999). The output will be a 1 x 1000 vector with probability of likes by the user i ( i from 0 to 999). We include a three dimensional embedding layer to convert the sparse user movie vector to a three dimensional embedding layer (see Schema below, from Google). The empirical rule of thumb is the dimension of the embedding layer is approximately (possible values)^0.25 (start with this number and further tune it to get optimal dimension).
Image embedding Pinterest example
Embedding Visualization - t-SNE
t-Distributed Stochastic Neighbor Embedding (t-SNE) is a non-linear technique for dimensionality reduction. It tries to map high-dimensional data to a lower-dimensional manifold, creating an embedding that attempts to maintain local structure within the data. It’s almost exclusively used for visualization because the output is stochastic (random) and it does not support transforming new data. Compared to PCA:
- t-SNE is computationally expensive and can take several hours on million-sample datasets where PCA will finish in seconds or minutes.
- PCA is a mathematical technique, but t-SNE is a probabilistic one.
- PCA is a linear method while t-SNE is a non-linear method.
- PCA concentrates on placing dissimilar data points apart in a lower dimension representation while t-SNE tries to represent similar data points close together. Therefore, the cluster segregation is better in the lower dimensional space using t-SNE.
- t-SNE is a stochastic method, meaning different runs with the same hyperparameters may produce different results. On the contrary, PCA is a deterministic method.
References:
- https://www.dslearn.org/embeddings/
- https://towardsdatascience.com/neural-network-embeddings-explained-4d028e6f0526
- https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture
- https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
- https://www.datacamp.com/community/tutorials/introduction-t-sne
- https://towardsdatascience.com/an-introduction-to-t-sne-with-python-example-5a3a293108d1
Comments
Join the discussion for this article on this ticket. Comments appear on this page instantly.