A Good Mastery of PySpark
What is PySpark?
Apache Spark is a fast and general-purpose cluster computing system. At its core, it is a generic engine for processing large amounts of data. Spark is written in Scala and runs on the Java Virtual Machine. Spark has built-in components for processing streaming data, machine learning, graph processing, and even interacting with data via SQL. It provides high-level APIs in Java, Scalar, Python and R. Its Python API is called PySpark.
PySpark offers PySpark Shell which links the Python API to the spark core and initializes the Spark context. Majority of data scientists and analytics experts today use Python because of its rich library set. Integrating Python with Spark is a boon to them.
How to install PySpark?
- Download Java 8 or above here
- Install Spark here
- Select the latest Spark release, a prebuilt package for Hadoop, and download it directly and move it to the designated folder
- Download winutils.exe, then place it in the bin folder of the Hadoop prebuilt package; make sure you follow the instructions to change the PATH.
- Note: make sure that you are installing 64 bit java, so that to put in the ‘Program Files’ instead of ‘Program Files (x86)’ folder. The latter one will give you ‘can’t find file path error’.
- Install pyspark using
pip install pyspark (you need to have both Python and Spark installed before this step) in Anaconda command prompt
- Install findspark using
pip install findspark in Anaconda command prompt so that you can use pyspark in any IDE including Jupyter Notebook
How does Spark work
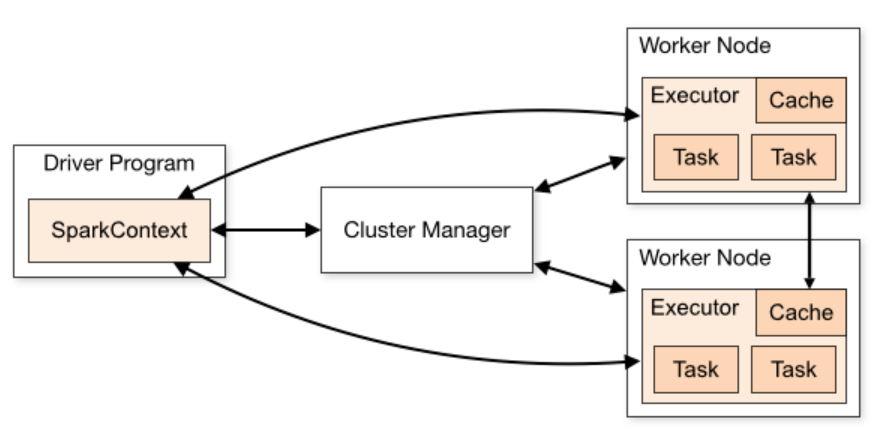
Spark Cluster Overview from Apache Spark
Cluster Manager
Accoring to Apache Spark official website, Spakr currently supports several cluster managers:
- Standalone – a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos – a general cluster manager that can also run Hadoop MapReduce and service applications.
- Hadoop YARN – the resource manager in Hadoop 2.
- Kubernetes – an open-source system for automating deployment, scaling, and management of containerized applications.
SparkContext
SparkContext is the main entry point for Spark functionality. It represents the connection to a Spark cluster, and can be used to create RDDs, accumulators, coordinate Spark applications and broadcast variables on that cluster. A Spark context is essentially a client of Spark’s execution environment and acts as the master of your Spark application. Creating a SparkContext is the most important step and the first step you need to create before using any Spark application.
The following code shows how to initiate a SparkContext in a local cluster (single-machine mode):
import pyspark
sc = pyspark.SparkContext('local', 'app name')
If you want to create a SparkContext in a cluster, you may need to handle authentication and a few other pieces of information specific to your cluster. You can set up those details similarly to the following:
conf = pyspark.SparkConf()
conf.setMaster('spark://head_node:56887')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)
RDD
RDD stands for Resilient Distributed Dataset. They are the elements that run and operate on multiple nodes to do parallel processing on a cluster. RDDs are immutable and can recover automatically in case of any failure. RDDs can be created directly from input files or a newly defined data as follows.
# create a RDD from input file
rdd = sc.textFile("data.txt")
# create a RDD from new data
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
RDDs support two types of operations: transformations and actions. Transformations create a new dataset from an existing one, while actions return a value after running a computation on the dataset. Spark just remember the transformations applied to some base dataset and compute only when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently.
lines = sc.textFile("data.txt")
# transformation, return a new dataset
lineLengths = lines.map(lambda s: len(s))
# action, return a new value
totalLength = lineLengths.reduce(lambda a, b: a + b)
Spark ML
Spark ML is a package aims to provide a uniform set of high-level APIs to help users create and tune practical machine learning pipelines. It is currently available only in Java and Scala.
Changing Python code to PySpark code
PySpark is the Python API for Spark. It allows data scientist to do big data processing and distributed computing without knowing Java or Scala.
For beginners, changing Python code to PySpark code is a good way to get familiar with PySpark. Below is a collection of common Python code used in data science and their PySpark version.
create pandas or PySpark dataframe
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
spark_conf = SparkConf().setMaster("local").setAppName("MyAppName")
sc = SparkContext(conf=spark_conf)
sqlContext = SQLContext(sc)
records = [{'color':"red"}, {'color':"blue"}, {'color':None}]
pandas_df = pd.DataFrame.from_dict(records)
pyspark_df = sqlContext.createDataFrame(records)
Spark dataframe to pandas dataframe
pandas_df = pyspark_df.toPandas()
filter data in pandas or PySpark dataframe
pandas_df[~pandas_df['color'].isin(["red"])]
pyspark_df.filter(~pyspark_df['color'].isin(['red'])).collect()
# pyspark_df.filter((df.col1< 3)&(df.col2 > 4))
drop columns
pandas_df = pandas_df.drop([col1, col2])
pyspark_df = pyspark_df.drop(col1, col2)
convert dataframe to numpy array
# python
df.col_name.values
# pyspark
np.array(df.select(col1, col2).collect())
dataframe dimension
print(len(pandas_df.index), len(pandas_df.columns))
print(pyspark_df.count(), len(pyspark_df.columns))
locate cretain elements
pandas_df[col_name].iloc[i]
pyspark_df.collect()[i][col_name]
update column content
# python
pandas_df.loc[:, col_name] = new_content
# pyspark, need to create another dataframe since RDDs are immutable
name = 'target_column'
udf = UserDefinedFunction(lambda x: 'new_value', StringType())
new_df = old_df.select(*[udf(column).alias(name) if column == name else column for column in old_df.columns])
add a new column to a dataframe
# python
pandas_df.loc[:, 'rate_type'] = pd.Series(np.array(rate_type))
# pyspark
rateUdf = udf(rate_type, ArrayType(StringType()))
pyspark_df = pyspark_df.withColumn('rate_type', rateUdf())
# Add a constant column to a PySpark dataframe:
from pyspark.sql.functions import lit
df.withColumn('new_column', lit(10))
map column names to lower case
pandas_df.columns = list[map(str.lower, pandas_df.columns)]
pyspark_df.toDF(*[c.lower() for c in df.columns])
rename columns
from pyspark.sql.functions import col
pandas_df = pandas_df.rename(index=str, columns={"supplier_conf_number": "confirmation_number"})
pyspark_df = pyspark_df.selectExpr("supplier_conf_number as confirmation_number")
group by
pandas_df.col_name.value_counts()
pyspark_df.groupBy('col_name').count().orderBy('count')
merge dataframes
merged_pandas_df = pd.merge(pandas_df1,pandas_df2[[col1, col2, col3]],on=[col1, col2], how='outer')
merged_pyspark_df = pyspark_df1.join(pyspark_df2, pyspark_df1['col1'] == pyspark_df2['col2'], "outer")
drop duplicates
pandas_df = pandas_df.drop_duplicates(subset=['col1', 'col2', 'col3'])
pyspark_df = pyspark_df.dropDuplicates(['col1', 'col2'])
drop null value
pandas_df = pandas_df.dropna(subset=[col_name], how = 'any')
pyspark_df = pyspark_df.filter(pyspark_df.col_name.isNotNull())
column multiplication
pandas_df[''new_col'] = pandas_df['col1'] * pandas_df['col2'] * pandas_df['col3']
pyspark_df = pandas_df.withColumn('new_col', pandas_df['col1'] * pandas_df['col2'] * pandas_df['col3'] )
one-hot encoding
# Python
pandas_df = pd.get_dummies(pandas_df, prefix_sep="__", columns=cat_columns)
# PySpark
import pyspark.sql.functions as F
# single column
categ = df.select('Continent').distinct().rdd.flatMap(lambda x:x).collect()
exprs = [F.when(F.col('Continent') == cat,1).otherwise(0).alias(str(cat)) for cat in categ]
df = df.select(exprs+df.columns)
# multiple columns:
for col_name in cat_columns:
categories = df.select(col_name).distinct().rdd.flatMap(lambda x : x).collect()
for category in categories:
function = udf(lambda item: 1 if item == category else 0, IntegerType())
new_column_name = col_name+'__'+category
df = df.withColumn(new_column_name, function(col(col_name)))
save to csv file
pandas_df.to_csv(local_file_path, sep=',', header=True, index=False)
# to one file with random name in one folder with name as local_file_path
pyspark_df.coalesce(1).write.csv(local_file_path, header=True)
pyspark_df.coalesce(1).write.option("header", "true").csv("local_file_path.csv")
# to multiple files with random name in one folder with name as local_file_path
pyspark_df.write.csv(local_file_path, header=True)
Reference:
- https://www.tutorialspoint.com/pyspark/index.htm
- https://realpython.com/pyspark-intro/
- https://medium.com/@naomi.fridman/install-pyspark-to-run-on-jupyter-notebook-on-windows-4ec2009de21f
- https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-SparkContext.html
A Good Mastery of PySpark
What is PySpark?
Apache Spark is a fast and general-purpose cluster computing system. At its core, it is a generic engine for processing large amounts of data. Spark is written in Scala and runs on the Java Virtual Machine. Spark has built-in components for processing streaming data, machine learning, graph processing, and even interacting with data via SQL. It provides high-level APIs in Java, Scalar, Python and R. Its Python API is called PySpark.
PySpark offers PySpark Shell which links the Python API to the spark core and initializes the Spark context. Majority of data scientists and analytics experts today use Python because of its rich library set. Integrating Python with Spark is a boon to them.
How to install PySpark?
- Download Java 8 or above here
- Install Spark here
- Select the latest Spark release, a prebuilt package for Hadoop, and download it directly and move it to the designated folder
- Download winutils.exe, then place it in the bin folder of the Hadoop prebuilt package; make sure you follow the instructions to change the PATH.
- Note: make sure that you are installing 64 bit java, so that to put in the ‘Program Files’ instead of ‘Program Files (x86)’ folder. The latter one will give you ‘can’t find file path error’.
- Install pyspark using
pip install pyspark(you need to have both Python and Spark installed before this step) in Anaconda command prompt - Install findspark using
pip install findsparkin Anaconda command prompt so that you can use pyspark in any IDE including Jupyter Notebook
How does Spark work
Spark Cluster Overview from Apache Spark
Cluster Manager
Accoring to Apache Spark official website, Spakr currently supports several cluster managers:
- Standalone – a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos – a general cluster manager that can also run Hadoop MapReduce and service applications.
- Hadoop YARN – the resource manager in Hadoop 2.
- Kubernetes – an open-source system for automating deployment, scaling, and management of containerized applications.
SparkContext
SparkContext is the main entry point for Spark functionality. It represents the connection to a Spark cluster, and can be used to create RDDs, accumulators, coordinate Spark applications and broadcast variables on that cluster. A Spark context is essentially a client of Spark’s execution environment and acts as the master of your Spark application. Creating a SparkContext is the most important step and the first step you need to create before using any Spark application.
The following code shows how to initiate a SparkContext in a local cluster (single-machine mode):
import pyspark
sc = pyspark.SparkContext('local', 'app name')
If you want to create a SparkContext in a cluster, you may need to handle authentication and a few other pieces of information specific to your cluster. You can set up those details similarly to the following:
conf = pyspark.SparkConf()
conf.setMaster('spark://head_node:56887')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)
RDD
RDD stands for Resilient Distributed Dataset. They are the elements that run and operate on multiple nodes to do parallel processing on a cluster. RDDs are immutable and can recover automatically in case of any failure. RDDs can be created directly from input files or a newly defined data as follows.
# create a RDD from input file
rdd = sc.textFile("data.txt")
# create a RDD from new data
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
RDDs support two types of operations: transformations and actions. Transformations create a new dataset from an existing one, while actions return a value after running a computation on the dataset. Spark just remember the transformations applied to some base dataset and compute only when an action requires a result to be returned to the driver program. This design enables Spark to run more efficiently.
lines = sc.textFile("data.txt")
# transformation, return a new dataset
lineLengths = lines.map(lambda s: len(s))
# action, return a new value
totalLength = lineLengths.reduce(lambda a, b: a + b)
Spark ML
Spark ML is a package aims to provide a uniform set of high-level APIs to help users create and tune practical machine learning pipelines. It is currently available only in Java and Scala.
Changing Python code to PySpark code
PySpark is the Python API for Spark. It allows data scientist to do big data processing and distributed computing without knowing Java or Scala.
For beginners, changing Python code to PySpark code is a good way to get familiar with PySpark. Below is a collection of common Python code used in data science and their PySpark version.
create pandas or PySpark dataframe
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
spark_conf = SparkConf().setMaster("local").setAppName("MyAppName")
sc = SparkContext(conf=spark_conf)
sqlContext = SQLContext(sc)
records = [{'color':"red"}, {'color':"blue"}, {'color':None}]
pandas_df = pd.DataFrame.from_dict(records)
pyspark_df = sqlContext.createDataFrame(records)
Spark dataframe to pandas dataframe
pandas_df = pyspark_df.toPandas()
filter data in pandas or PySpark dataframe
pandas_df[~pandas_df['color'].isin(["red"])]
pyspark_df.filter(~pyspark_df['color'].isin(['red'])).collect()
# pyspark_df.filter((df.col1< 3)&(df.col2 > 4))
drop columns
pandas_df = pandas_df.drop([col1, col2])
pyspark_df = pyspark_df.drop(col1, col2)
convert dataframe to numpy array
# python
df.col_name.values
# pyspark
np.array(df.select(col1, col2).collect())
dataframe dimension
print(len(pandas_df.index), len(pandas_df.columns))
print(pyspark_df.count(), len(pyspark_df.columns))
locate cretain elements
pandas_df[col_name].iloc[i]
pyspark_df.collect()[i][col_name]
update column content
# python
pandas_df.loc[:, col_name] = new_content
# pyspark, need to create another dataframe since RDDs are immutable
name = 'target_column'
udf = UserDefinedFunction(lambda x: 'new_value', StringType())
new_df = old_df.select(*[udf(column).alias(name) if column == name else column for column in old_df.columns])
add a new column to a dataframe
# python
pandas_df.loc[:, 'rate_type'] = pd.Series(np.array(rate_type))
# pyspark
rateUdf = udf(rate_type, ArrayType(StringType()))
pyspark_df = pyspark_df.withColumn('rate_type', rateUdf())
# Add a constant column to a PySpark dataframe:
from pyspark.sql.functions import lit
df.withColumn('new_column', lit(10))
map column names to lower case
pandas_df.columns = list[map(str.lower, pandas_df.columns)]
pyspark_df.toDF(*[c.lower() for c in df.columns])
rename columns
from pyspark.sql.functions import col
pandas_df = pandas_df.rename(index=str, columns={"supplier_conf_number": "confirmation_number"})
pyspark_df = pyspark_df.selectExpr("supplier_conf_number as confirmation_number")
group by
pandas_df.col_name.value_counts()
pyspark_df.groupBy('col_name').count().orderBy('count')
merge dataframes
merged_pandas_df = pd.merge(pandas_df1,pandas_df2[[col1, col2, col3]],on=[col1, col2], how='outer')
merged_pyspark_df = pyspark_df1.join(pyspark_df2, pyspark_df1['col1'] == pyspark_df2['col2'], "outer")
drop duplicates
pandas_df = pandas_df.drop_duplicates(subset=['col1', 'col2', 'col3'])
pyspark_df = pyspark_df.dropDuplicates(['col1', 'col2'])
drop null value
pandas_df = pandas_df.dropna(subset=[col_name], how = 'any')
pyspark_df = pyspark_df.filter(pyspark_df.col_name.isNotNull())
column multiplication
pandas_df[''new_col'] = pandas_df['col1'] * pandas_df['col2'] * pandas_df['col3']
pyspark_df = pandas_df.withColumn('new_col', pandas_df['col1'] * pandas_df['col2'] * pandas_df['col3'] )
one-hot encoding
# Python
pandas_df = pd.get_dummies(pandas_df, prefix_sep="__", columns=cat_columns)
# PySpark
import pyspark.sql.functions as F
# single column
categ = df.select('Continent').distinct().rdd.flatMap(lambda x:x).collect()
exprs = [F.when(F.col('Continent') == cat,1).otherwise(0).alias(str(cat)) for cat in categ]
df = df.select(exprs+df.columns)
# multiple columns:
for col_name in cat_columns:
categories = df.select(col_name).distinct().rdd.flatMap(lambda x : x).collect()
for category in categories:
function = udf(lambda item: 1 if item == category else 0, IntegerType())
new_column_name = col_name+'__'+category
df = df.withColumn(new_column_name, function(col(col_name)))
save to csv file
pandas_df.to_csv(local_file_path, sep=',', header=True, index=False)
# to one file with random name in one folder with name as local_file_path
pyspark_df.coalesce(1).write.csv(local_file_path, header=True)
pyspark_df.coalesce(1).write.option("header", "true").csv("local_file_path.csv")
# to multiple files with random name in one folder with name as local_file_path
pyspark_df.write.csv(local_file_path, header=True)
Reference:
- https://www.tutorialspoint.com/pyspark/index.htm
- https://realpython.com/pyspark-intro/
- https://medium.com/@naomi.fridman/install-pyspark-to-run-on-jupyter-notebook-on-windows-4ec2009de21f
- https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-SparkContext.html
Comments
Join the discussion for this article on this ticket. Comments appear on this page instantly.